




Github had a peculiar challenge that saw unusual push failures to some repositories. 😮
Every day, about 56 million developers use GitHub, working on over 200 million repositories. Few repositories get thousands of updates in a single day. These are called monorepo - which stores the code of many projects in the same repository. GitHub also maintains one of such repositories github/github

Such respos were seeing performance problems that were impacting their ability to complete push operations. Despite having a scalable architecture and optimised processes, why was GitHub facing this issue? 🤔
GitHub runs a maintenance routine after every 50 git push operations. So, for large respos, it got scheduled frequently, even when developers were still pushing changes to the repo. Failing to complete the maintenance within a window impacted the push and update operations.
During maintenance, GitHub runs git repack, which compresses a set of objects to a pack. It does it to reduces disk storage. During this process, Git tries to find pairs of objects related to one another, but this takes a lot of time. To make it faster, GitHub searched for pairs within a sliding window over an array of all objects. Now you know how a basic understanding of data structures helps. 😬
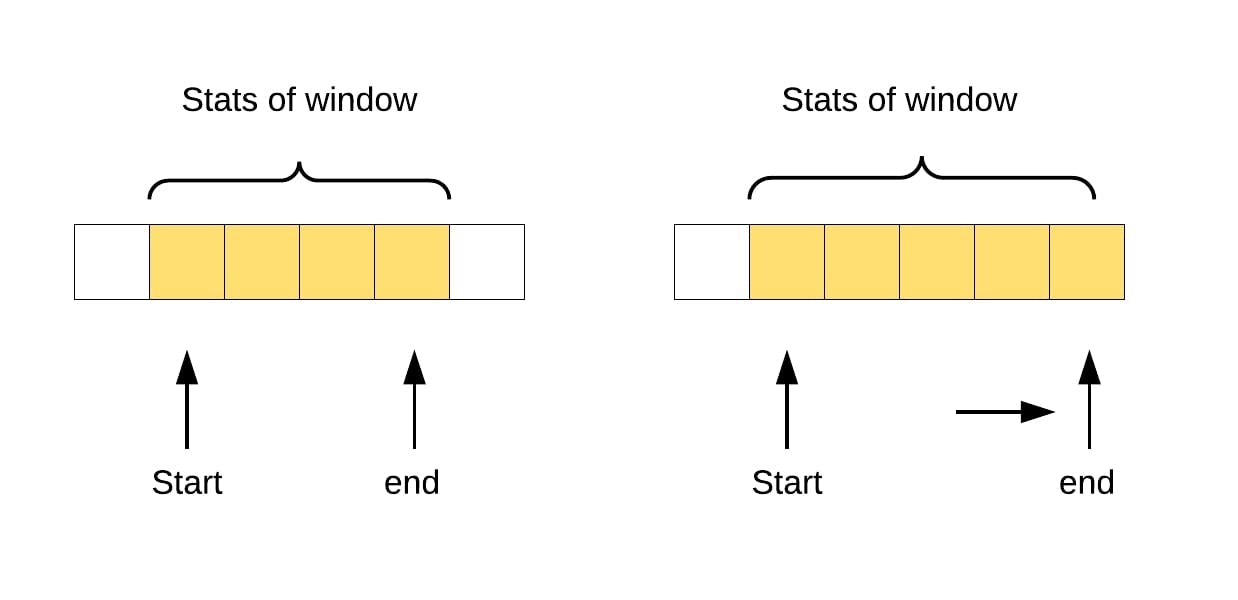 image credits: Xiaokang's Study Notes
image credits: Xiaokang's Study Notes
GitHub also increased the push operations to file servers and optimised replica creation across 3 data centers. By limiting expensive comparisons, GitHub eliminated nearly all of its maintenance failures.
Having challenges and failures are common, but how you approach solving them sets you apart! ✨
Do like and share this article if you enjoyed reading it!
I write about system design and break down how companies build their system. Join my weekly newsletter to get more insights! Connect with me on LinkedIn and Twitter