




We often complain about the delivery delays and average service of e-commerce companies like Flipkart or Amazon, but the technology and process behind optimising these logistics are fascinating!
With over 10 million shipments per month, how does Flipkart handle its logistics? 🤔
Even before the shipment happens, Flipkart identifies sources in which the item is available, the lanes which connect the source and destination, and the services that deliver the product.
The challenging part is to model the storage and retrieval of such information. Flipkart recently reduced the data footprints from 300 GB to 150 MB. That's a 2000x reduction. 📉

Earlier, it used to store this information in a sharded DB that mapped the source-destination pin codes with cost, services offered, delivery date, etc. It resulted in about 750 million keys. It comprised 80 shards with 4 GB of data each, resulting in 300 GB of data footprint.
With many iterations and known data structures, they optimised the model to store all data under 150 MB of App's heap memory. 😮
The idea was to create a graph with destinations and service information as nodes. Each destination would link to multiple service nodes which had information like source, delivery time, cost, etc. This was further represented as 2 arrays - one storing the destination ordinals which pointed to an array with service information.
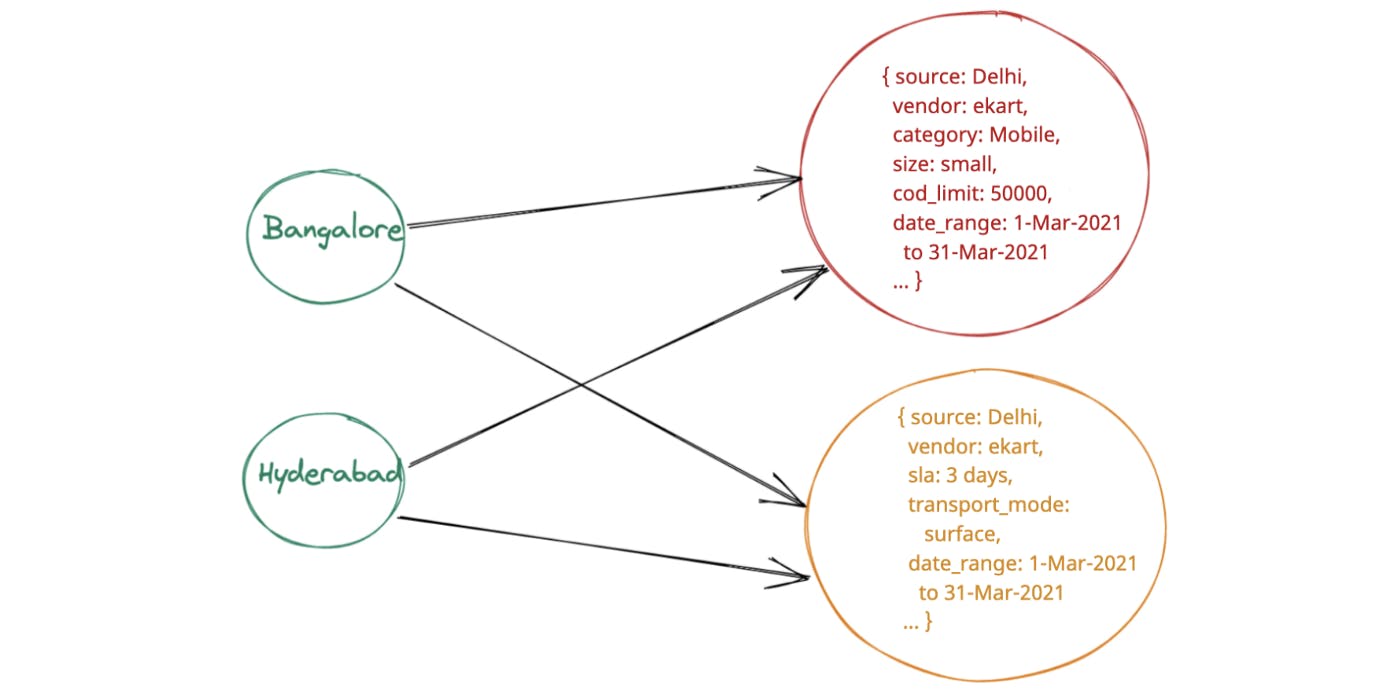 image source: Flipkart
image source: Flipkart
Now, it could easily filter out the required information from the destination and few parameters.
This optimisation shows direct applications of known data structures like graphs, arrays, pointers, etc. Although you don't need to know how to invert a binary tree, having a fundamental understanding of data structures does help!
Do like and share this article if you enjoyed reading it!
I write about system design and break down how companies build their system. Join my newsletter to get more insights! Connect with me on LinkedIn and Twitter